
Cloud Data Flow Guide: Triggers, Architecture & Security Explained

Table of Contents

Every industry is hyper-connected and data-driven. This means that organizations of all sizes need to rely on cloud data flow architectures to move, process, and analyze information as quickly and efficiently as possible—ideally in real-time if resources allow. Data sources for enterprise organizations usually include high-frequency IoT telemetry, log streams, or large-scale ETL workloads, so modern pipelines must be able to deliver secure, scalable, and low-latency data processing across hybrid and multi-cloud environments, because organizations these days don’t often rely on just one cloud environment type.
Data cloud-triggered flow patterns—where processing begins automatically in response to events—organizations can further accelerate insights and reduce operational friction.
Cloud platforms such as PSSC Labs, GCP Dataflow, AWS Glue, and Azure Data Factory offer powerful capabilities for stream and batch processing, but taking full advantage of their value requires a deep understanding of core concepts, architectural patterns, trigger mechanisms, cross-platform trade-offs, and cloud data flow security.
This article explores these facets in detail, from designing resilient architectures to implementing robust monitoring and optimization strategies that ensure performance and cost efficiency.
What is Cloud Data Flow?
Cloud data flow refers to the continuous movement, transformation, and processing of data across distributed systems in the cloud. Modern architectures include everything from ingesting data streams from IoT devices and enterprise applications to performing real-time analytics and persisting the results in cloud storage or data warehouses.
The drivers behind this shift include:
- Explosion of real-time data: The proliferation of connected devices, social media activity, and transactional systems has created a constant demand for processing high-velocity data. Traditional batch processing is often too slow to deliver timely insights.
- Hybrid environments: Enterprises increasingly operate in mixed infrastructures. Some workloads run in public cloud, others in private data centers, and many span both in a hybrid cloud environment. A well-architected data flow cloud design ensures seamless integration between these environments.
- Need for secure and scalable pipelines: As data flows become mission-critical, cloud data flow security—encompassing encryption, authentication, and compliance—must be baked into every pipeline stage. Scalability is equally critical, as workloads can spike unpredictably.
Several cloud platforms have built specialized services to orchestrate these flows. GCP Cloud Dataflow, for example, provides serverless stream and batch processing with automatic scaling, making it ideal for cloud data flow GCP workloads. AWS Glue and Azure Data Factory offer similar capabilities, each with unique integrations into their respective ecosystems. These services make it easier for organizations to design, monitor, and optimize pipelines, often supported by a cloud data flow diagram to visualize dependencies and transformations.
For organizations looking to build or modernize these architectures, PSSC Labs delivers custom-engineered high-performance data processing solutions that integrate seamlessly with cloud-native services. Their expertise in secure, scalable, and compliant pipeline design ensures your data cloud-triggered flow strategy is optimized for both current needs and future growth.
Core Concepts of Cloud Data Flow
Source
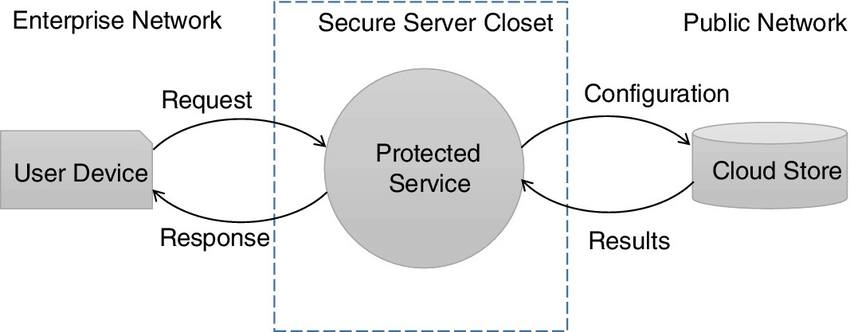
Another important part of understanding cloud data flow is differentiating it from related concepts and identifying its core operational modes. Cloud data flow encompasses orchestrating event-driven or scheduled processes to ingest, transform, and deliver data across cloud environments, often visualized in a cloud data flow diagram.
Here’s an example cloud data flow diagram for a three-tier architecture environment:
1. Data Flow vs. Data Pipeline vs. ETL/ELT
Although often used interchangeably, these terms have distinct scopes in modern architectures:
| Term | Scope & Focus | Typical Use Case | Key Difference |
| Data Flow | The real-time or scheduled movement of data through various processing stages | Data cloud-triggered flow in response to events | Emphasizes movement and orchestration, not just transformation |
| Data Pipeline | A structured sequence of data processing tasks | Multi-step workflows in data flow cloud systems | Broader; includes flows, storage, and monitoring |
| ETL/ELT | Extract, Transform, Load (or Extract, Load, Transform) | Loading data into a warehouse for analysis | ETL/ELT is a specific type of pipeline focused on structured data preparation |
2. Stream vs. Batch vs. Micro-Batch Processing
Processing mode is a critical design choice in cloud data flow, GCP, or any other platform:
| Mode | Latency | Data Volume Handling | Common Applications |
| Stream Processing | Milliseconds to seconds | Continuous, unbounded data | Fraud detection, IoT monitoring, log analysis |
| Batch Processing | Minutes to hours | Large, bounded datasets | End-of-day reports, historical analytics |
| Micro-Batch | Seconds to minutes | Small batches at fixed intervals | Real-time dashboards with tolerable delays |
Services like GCP Cloud Dataflow allow hybrid approaches, enabling pipelines to shift between stream and batch modes based on business needs.
3. Stateless vs. Stateful Processing in Cloud-Native Architectures
The choice between stateless and stateful operations impacts cloud data flow security, scaling strategies, and fault tolerance:
| Approach | State Management | Advantages | Challenges |
| Stateless | No retention of prior data state between events | Scales easily, fault-tolerant | Limited contextual processing |
| Stateful | Maintains contextual state across events | Enables complex event processing, aggregations | More resource-intensive, requires robust fault recovery |
Overview of Data Cloud-Triggered Flow Concepts
A data cloud-triggered flow (often initiated in Salesforce but can be used in other platforms) is initiated by specific events, such as sensor readings, API calls, or business transactions, and is processed automatically without manual intervention. This approach enables truly reactive architectures, where data movement and transformation occur in near real time, often coupled with cloud data flow analysis to optimize performance and reliability.
Cloud Data Flow Architecture: Components & Patterns

A robust cloud data flow architecture follows a medallion architecture or layered design—spanning data ingestion, transformation, and delivery—to ensure secure, scalable, and maintainable pipelines. Whether deployed using PSSC Labs engineered solutions, GCP Cloud Dataflow, AWS Glue, Azure Data Factory, or other platforms, these components operate cohesively to handle both data cloud-triggered flow and schedule-based execution. PSSC Labs designs architectures that integrate seamlessly with these services while optimizing for performance, security, and compliance—making them a strong choice for organizations managing complex data environments.
1. Sources
Data flows begin with ingestion points that feed the pipeline. Common sources include:
- APIs: Streaming updates from SaaS apps, payment gateways, or partner platforms.
- Logs: Application and infrastructure logs for monitoring and cloud data flow analysis.
- IoT Devices: Continuous sensor and telemetry streams demanding low-latency processing.
- Databases: Both transactional (OLTP) and analytical (OLAP) systems.
- Cloud Storage: Object stores like GCS, S3, or Azure Blob, often triggering data cloud trigger flow events when new files arrive.
2. Transformations
Once ingested, data undergoes processing steps to prepare it for consumption:
- ETL/ELT Logic: Extraction and transformation either before or after loading into storage.
- Enrichment: Adding context by joining with reference data or external APIs.
- Windowing: Grouping event streams into time-based chunks for analytics.
- Joins: Merging multiple data streams to create a unified view.
Platforms like GCP Cloud Dataflow excel here by offering native support for parallel, distributed transformations that scale elastically. PSSC Labs can design custom pipelines that leverage these capabilities while ensuring cloud data flow security and performance requirements are met.
3. Sinks
The final destination of the processed data often falls into one of these categories:
- Data Warehouses: e.g., BigQuery, Snowflake, Redshift for advanced analytics.
- Data Lakes: Storing raw or semi-structured data for future use.
- NoSQL/SQL Stores: Supporting high-availability transactional or semi-structured queries.
- Real-Time Dashboards: Pushing updates directly into visualization layers for operational monitoring.
4. Event-Driven vs. Schedule-Based Patterns
- Event-Driven: Data cloud-triggered flow: Pipelines that start upon specific triggers such as a new file in cloud storage, an IoT reading, or a message in a queue. These deliver near-instant responsiveness, crucial for fraud detection, alerting, and customer engagement.
- Schedule-Based: Pipelines executed at fixed intervals (hourly, daily, etc.)—often used for batch aggregation, compliance reporting, or historical analysis.
5. Stateless vs. Stateful in Distributed Environments
In distributed data flow cloud environments, the choice between stateless and stateful operations is critical:
- Stateless operations scale linearly and recover quickly, but lack historical context.
- Stateful operations maintain context across events, enabling advanced patterns like rolling averages, sessionization, and trend detection—while demanding stronger cloud data flow security and fault tolerance strategies.
Trigger Mechanisms in Cloud Data Flows
A data cloud-triggered flow is a process that starts automatically in response to a specific event or condition within a cloud environment. Unlike purely scheduled jobs, these flows react instantly to data changes or system events, enabling real-time responsiveness and reducing latency in cloud data flow architectures.
1. File-Based Triggers
Ingest pipelines can be initiated when a new file is uploaded to cloud storage services. For example:
- Google Cloud Storage can fire events to start a GCP Cloud Dataflow job when a CSV or JSON file arrives.
- AWS S3 triggers can initiate AWS Lambda functions or Glue jobs. This approach is common for data flow cloud pipelines handling batch-oriented datasets, but still requires low-latency processing.
2. Pub/Sub Event Triggers (Real-Time)
Messaging systems such as Google Pub/Sub or AWS SNS/SQS can initiate pipelines when an event occurs—ideal for IoT telemetry, payment processing, or log analytics. When paired with cloud data flow analysis, event-triggered processing can dynamically adapt transformations based on payload metadata.
3. Scheduled Batch Triggers
While not “event-driven” in the strict sense, scheduled triggers (e.g., Cloud Scheduler, AWS EventBridge, or Azure Logic Apps) remain vital for workloads that aggregate or process data at defined intervals. This pattern is often used alongside cloud data flow GCP batch jobs for compliance reports or daily data enrichment tasks.
4. Manual or API-Based Initiation
In some cases, teams need to trigger a data cloud trigger flow manually—via CLI, web UI, or REST API—especially during ad hoc analysis, troubleshooting, or reprocessing scenarios.
5. Orchestration Tools
Complex workflows often require orchestrators to manage dependencies, retries, and branching logic:
- Apache Airflow (self-managed or via Google Cloud Composer) can chain together event-based and schedule-based tasks.
- These orchestrators are essential for hybrid pipelines that blend data cloud-triggered flow events with downstream analytics, machine learning model retraining, and dashboard updates.
Cross-Platform Comparison: AWS, Azure, and GCP
Each major cloud provider offers its own ecosystem for building cloud data flow solutions, often pairing an orchestration or transformation service with an event ingestion layer. While the core capabilities—real-time ingestion, transformation, and delivery—are similar, differences emerge in latency, integration depth, and pricing models.
AWS: Glue + Kinesis Data Firehose
- AWS Glue handles ETL/ELT transformations and can be triggered by S3 events, EventBridge schedules, or APIs.
- Kinesis Data Firehose ingests streaming data and delivers it to S3, Redshift, Elasticsearch, or custom HTTP endpoints.
- Strong integration with AWS-native services, though cross-cloud workflows require extra configuration.
Azure: Data Factory + Stream Analytics
- Azure Data Factory focuses on orchestration and ETL pipelines, integrating seamlessly with both on-prem and Azure-hosted data sources.
- Azure Stream Analytics processes streaming data from Event Hubs, IoT Hub, or Blob Storage, supporting data flow cloud use cases in near real time.
- Tight integration with Microsoft ecosystem services like Power BI and Synapse Analytics.
Google Cloud: Dataflow + Pub/Sub
- GCP Cloud Dataflow is a fully managed, serverless stream and batch processing service supporting both data cloud-triggered flow and scheduled pipelines.
- Pub/Sub handles global-scale message ingestion, providing millisecond-level latency for IoT, analytics, and AI workloads.
- Strong cross-region capabilities and native integration with BigQuery, Vertex AI, and other GCP services.
Comparison Table
| Platform | Ingestion Service | Processing Service | Latency (Typical) | Ease of Use | Pricing Model | Integration Strength |
| AWS | Kinesis Data Firehose | AWS Glue | Low (<1 sec for streams) | Moderate (steeper learning curve for Glue jobs) | Pay per GB processed and per job run | Deep AWS ecosystem, weaker cross-cloud |
| Azure | Event Hubs / IoT Hub | Data Factory + Stream Analytics | Low for streams, higher for batch | High for Azure users, moderate otherwise | Consumption-based | Strong Microsoft stack integration |
| GCP | Pub/Sub | Cloud Dataflow | Very low (ms-level) for streams | High (serverless, auto-scaling) | Pay per vCPU/hr + data processed | Tight GCP service integration, multi-region strengths |
Cloud Data Flow Security Considerations

As cloud data flow pipelines become mission-critical, security must be embedded into every layer—from ingestion to processing to delivery. A breach or misconfiguration in a cloud-triggered flow can lead to unauthorized access, data leakage, or compliance violations, especially in regulated industries.
Encryption in Transit and at Rest
- In Transit: All data flowing between components—whether between GCP Cloud Dataflow and Pub/Sub, or AWS Glue and S3—should use TLS 1.2+ encryption.
- At Rest: Services like BigQuery, Redshift, and Azure Data Lake encrypt stored data using AES-256 or provider-managed keys. For sensitive workloads, customer-managed encryption keys (CMEK) or customer-supplied encryption keys (CSEK) provide added control.
Identity and Access Management (IAM) Models
- Use the principle of least privilege to restrict access to pipeline components.
- In data flow cloud deployments, assign separate service accounts for ingestion, transformation, and output stages to minimize blast radius.
- Cross-platform IAM mapping is critical when orchestrating flows across AWS, Azure, and GCP.
Securing Triggers
- Pub/Sub: Enforce topic-level IAM and signed push endpoints to prevent unauthorized message injection.
- Cloud Storage Buckets: Restrict write and read triggers to trusted service accounts, and use object versioning for rollback protection.
VPC Service Controls and Private IP Ranges
- For cloud data flow GCP workloads, VPC Service Controls create a security perimeter around sensitive resources to mitigate data exfiltration risks.
- Use private IP ranges for inter-service communication to avoid exposure over the public internet, especially in data flow cloud architectures spanning multiple services.
Auditing, Observability, and Role-Based Logging
- Enable audit logs for every component of the data cloud trigger flow, including orchestration tools like Apache Airflow or Google Cloud Composer.
- Role-based logging ensures that sensitive fields are masked or restricted based on user permissions.
- Continuous cloud data flow analysis of audit data can help detect anomalies, such as unusual trigger patterns or unauthorized access attempts.
Visualization & Monitoring of Cloud Data Flows
In modern cloud data flow environments, proactive monitoring and visualization are essential to ensure pipeline reliability, performance, and security. Observability helps identify bottlenecks before they impact SLAs, while visual dashboards provide stakeholders with real-time operational awareness of data cloud-triggered flow activity.
Monitoring Tools
Monitoring capabilities vary across platforms, with each offering native solutions tailored to its ecosystem. Stackdriver (Google Cloud Monitoring) delivers built-in metrics for GCP Cloud Dataflow, Pub/Sub, and related services, tracking latency, throughput, and error rates in real time. CloudWatch (AWS) provides extensive coverage for AWS Glue, Kinesis, and S3-triggered flows, enabling the creation of alarms and automated remediation workflows. Azure Monitor offers similar functionality, monitoring Azure Data Factory, Stream Analytics, and storage-triggered data flow cloud pipelines to ensure health and performance.
Real-Time Dashboards and Performance Metrics
Real-time dashboards offer teams the ability to visualize operational metrics—such as event throughput, queue depth, and transformation times—making it easier to detect anomalies and optimize performance before issues escalate. These visualizations also bring cloud data flow analysis to a broader audience, including operations teams, data engineers, and business analysts, fostering shared situational awareness across the organization.
Integrating With Third-Party Observability Tools
Beyond native monitoring, integrating third-party observability tools can enhance visibility across multi-cloud environments. Datadog consolidates metrics, logs, and traces from diverse sources, allowing for deeper correlation in complex data flow cloud architectures. Grafana offers flexible, customizable dashboards for time-series and aggregated metrics, and can seamlessly pull data from Stackdriver, CloudWatch, or Prometheus exporters to create unified operational views.
Debugging Data Flow Errors and Latency Bottlenecks
When a data cloud trigger flow encounters errors or experiences latency issues, pinpointing the root cause becomes essential for quick recovery. This involves analyzing service-specific error logs, such as GCP Dataflow job details or AWS Glue error reports, and tracing latency to determine whether bottlenecks occur in ingestion, transformation, or delivery stages. Teams may also test components in isolation, running partial pipelines to validate transformations independently from upstream or downstream dependencies. Combined with continuous monitoring and automated alerting, these practices ensure both cloud data flow security and operational performance remain within desired thresholds.
Cloud Data Flow Optimization Strategies
Optimizing a cloud data flow architecture ensures that pipelines not only perform efficiently but also scale cost-effectively. Whether in GCP Cloud Dataflow, AWS Glue, or Azure Data Factory, these strategies help improve throughput, reduce latency, and control operational expenses for both scheduled and data cloud-triggered flow workloads. PSSC Labs works with organizations to implement these strategies in tailored high-performance environments, ensuring that optimizations are aligned with both technical and business objectives.
Data Sharding and Parallelism
Partitioning data into shards enables parallel processing across multiple workers, dramatically improving throughput in data flow cloud environments. Key practices include:
- Partition datasets are divided into evenly sized shards to balance the load.
- Choose shard keys carefully to avoid skew and ensure uniform distribution.
- Leverage platform-specific parallelism features (e.g., Dataflow workers, Kinesis shards).
Autoscaling and Dynamic Resource Provisioning
Autoscaling ensures that resources adjust automatically to match workload demand, reducing cost and avoiding over-provisioning. Examples include:
- GCP Cloud Dataflow adding/removing worker nodes based on incoming event volume.
- AWS Glue job bookmarking to efficiently resume interrupted processing.
- Defining scaling thresholds to meet SLA requirements while controlling costs.
Watermarking and Time-Windowing for Real-Time Pipelines
In streaming workloads, these techniques improve timeliness and accuracy:
- Watermarking defines when all data for a given window is considered complete, reducing delays caused by late events.
- Time-windowing processes data in fixed or sliding intervals, enabling prompt analytics without sacrificing precision.
- Combining watermarking with time-windowing in cloud data flow analysis improves dashboard accuracy and alert responsiveness.
Cost Optimization With Pre-Aggregations and Upstream Filtering
Processing raw, high-volume streams without pre-filtering can lead to unnecessary storage and compute costs. By applying filtering logic and pre-aggregations early—ideally at the ingestion stage—pipelines minimize the amount of data flowing through expensive transformation and storage layers. For data cloud trigger flow workloads, this not only reduces cloud spending but also accelerates downstream analytics.
Conclusion
Cloud data flows are at the heart of real-time analytics, operational intelligence, and modern application integration. By understanding the distinctions between data flows, pipelines, and ETL/ELT processes—and by mastering concepts such as event-driven triggers, stateless versus stateful processing, and multi-cloud security models—organizations can build architectures that are both agile and future-ready. The key lies in pairing strong technical design with proactive monitoring, robust governance, and continuous optimization, ensuring that every data cloud-triggered flow delivers maximum business value without compromising security or cost efficiency.
If your organization is ready to elevate its cloud data flow capabilities, PSSC Labs can help you design and deploy tailored high-performance solutions.
With expertise in secure, scalable, and compliant data architectures, PSSC Labs enables you to process and analyze data at scale—whether in the cloud, on-premises, or hybrid environments to unlock actionable insights faster and with greater confidence.
Reach out to us today to get started.