What Is a Parallel File System? HPC Storage Explained

Table of Contents

High-performance computing (HPC) applications generate and process data at scales that traditional file systems cannot handle. A parallel file system overcomes these limitations by distributing data and metadata across multiple storage servers, enabling simultaneous, high-speed access for thousands of compute nodes.
Whether it’s training massive AI models, simulating climate patterns, or processing genomic data, parallel file systems provide the throughput, scalability, and reliability required to keep HPC workloads running at full speed.
Parallel File System Basics and Core Concepts
A parallel file system delivers high-performance data access by spreading file operations across multiple storage servers, unlike traditional systems that process requests sequentially on a single server. This computing design is essential in HPC parallel file system deployments, enabling rapid handling of massive datasets for simulations, AI training, and large-scale analytics.
What Makes a File System “Parallel” vs. Traditional?
In a traditional file system, client requests are typically funneled through a single metadata and storage server, creating a bottleneck as workloads scale. A parallel file system architecture breaks this limitation by:
- Striping data across multiple storage nodes, allowing simultaneous reads/writes (we discuss more about data striping below).
- Distributing metadata management to avoid single points of contention.
- Leveraging high-bandwidth interconnects to minimize network latency.
This approach enables a parallel global file system view, meaning clients across a HPC cluster or cloud environment can access the same files concurrently, with no need for local duplication or synchronization delays.
Overview of How Parallelism Works in File I/O
In a parallel file system in HPC, files are split into blocks and striped across multiple storage targets. When a compute node requests data, multiple servers deliver different parts of the file in parallel. This process:
- Maximizes throughput by engaging multiple storage nodes for each I/O operation.
- Reduces latency because multiple requests are processed simultaneously instead of queued.
- Supports concurrency so hundreds or thousands of nodes can access the same dataset without I/O contention.
Key Performance Traits of a Parallel File System
- Throughput: Measured in gigabytes or terabytes per second, throughput scales with the number of storage nodes, making parallel file system storage ideal for large HPC workloads.
- Low Latency: High-speed interconnects and distributed metadata handling reduce I/O wait times, essential for real-time simulations and streaming analytics.
- Concurrency: Multiple processes can access different parts of a file simultaneously without locking overhead, enabling massive parallel workloads.
- Scalability: Designed to scale linearly by adding storage servers, an open source parallel file system, or a commercial solution like HPE parallel file system can grow to handle petabytes of data without degrading performance.
Parallel File System Architecture Deep Dive
A parallel file system architecture boosts I/O performance, availability, and scalability by distributing metadata and file data across specialized components. From open-source solutions like Lustre to commercial options like HPE parallel file systems, the core design remains consistent across HPC environments.
High-Level Architecture: Metadata Servers vs. Object Storage Targets (OSTs)
At the heart of a parallel file system in HPC are two key components:
- Metadata Servers (MDS): Handle file system namespace operations such as file creation, deletion, permissions, and directory listings. By separating metadata from file data, MDS operations can be processed in parallel with data I/O, reducing contention.
- Object Storage Targets (OSTs): Store the actual file data in object form. Each OST manages a portion of the dataset, enabling concurrent read/write operations from multiple compute nodes.
This separation allows thousands of HPC nodes to access data simultaneously without overwhelming a single server, a critical distinction in parallel file system vs NFS comparisons.
Striping and Data Layout Across Disks/Nodes
Data striping is the foundation of parallel I/O efficiency. Files are divided into fixed-size blocks and distributed across multiple OSTs:
- Wide Striping: Distributes data across many OSTs, maximizing aggregate throughput for large sequential workloads.
- Narrow Striping: Limits striping to fewer OSTs, optimizing for smaller files and reducing overhead.
- Parallel Global File System Layout: This layout ensures consistent, cluster-wide file visibility, so all nodes see the same logical structure regardless of where data physically resides.
In many HPC parallel file system deployments, the stripe count and stripe size are tunable parameters, allowing performance optimization for specific workloads such as life sciences, genome sequencing, or AI model training.
Caching, Locking, and Consistency Models
Efficient caching strategies are crucial to reducing disk access latency. Parallel file systems employ:
- Client-Side Caching: Frequently accessed blocks are stored locally on compute nodes.
- Server-Side Caching: Metadata and data caches on MDS/OSTs accelerate repeated requests.
Locking mechanisms ensure data integrity when multiple processes write to the same file:
- Byte-Range Locking: Locks specific portions of a file, enabling high concurrency.
- Extent-Based Locking: Optimizes lock granularity for large datasets.
Consistency models vary: some prioritize strict POSIX compliance for deterministic behavior, while others allow relaxed consistency to improve performance in high-throughput environments.
Fault Tolerance and Data Recovery Considerations
Given the scale of parallel file system storage, failures are inevitable—so redundancy and recovery are built in:
- Replication: Multiple copies of critical metadata and data blocks are stored across OSTs.
- Erasure Coding: Provides fault tolerance with lower storage overhead compared to full replication.
- Automatic Failover: If an MDS or OST fails, standby systems take over to prevent downtime.
- Self-Healing: Background processes detect and rebuild degraded or missing data without disrupting ongoing workloads.
These features make parallel file systems for life sciences, climate modeling, and AI research resilient against node failures, ensuring uninterrupted access to petabyte-scale datasets.
Diagram: Simplified Architecture Layout
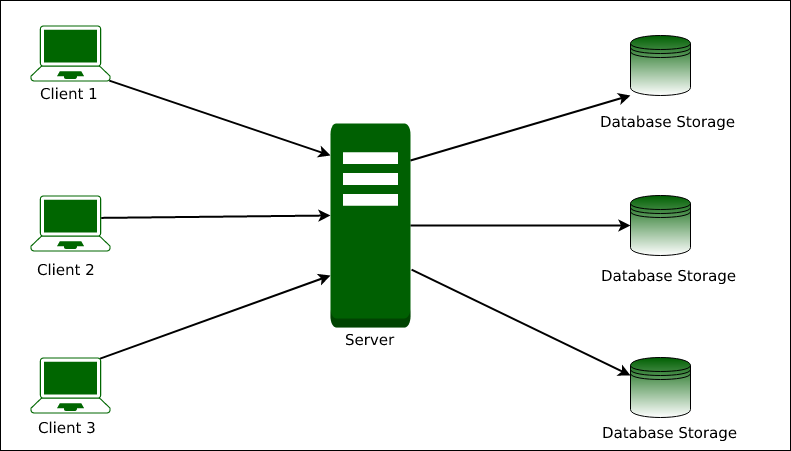
Parallel File Systems in HPC Environments

In HPC, storage throughput and I/O scalability are as vital as compute power. Parallel file system storage enables simultaneous reads and writes across nodes, ensuring the storage layer matches the extreme parallelism of modern workloads.
Why HPC Workloads Demand Parallel File System Storage
HPC applications in life sciences, genome sequencing, weather modeling, financial simulations, or AI training often process datasets so large that single-server storage solutions become a bottleneck. The challenges include:
- Massive Concurrency: Thousands of compute cores may need simultaneous access to the same dataset. A parallel file system in HPC eliminates I/O queuing by distributing workloads across many object storage targets.
- High-Throughput Requirements: Scientific models and AI workloads can demand aggregate bandwidth in the tens or hundreds of GB/s. Striping data across multiple OSTs allows the storage to scale linearly with demand.
- Low-Latency Checkpointing: HPC applications often save “checkpoint” states during long-running simulations. A parallel global file system accelerates these operations, reducing downtime in case of job restarts.
- Scalable Data Retention: Whether storing petabytes of molecular simulation data or satellite imagery, a HPC parallel file system can expand seamlessly without disrupting active workloads.
While NFS may suffice for smaller cluster workloads, only an authentic parallel architecture can sustain the scale and speed needed in exascale-class environments.
Integration With HPC Schedulers and MPI Workloads
A well-implemented parallel file system architecture integrates tightly with job schedulers like SLURM, PBS Pro, and LSF to ensure data availability aligns with compute scheduling. Key integration points include:
- Pre-Staging Data: Files can be moved or replicated onto specific OSTs before a job starts, minimizing startup delays.
- I/O-Aware Scheduling: Schedulers can place jobs on compute nodes physically closer (in network topology) to the data, reducing latency.
- MPI-Aware I/O: Parallel file systems often optimize for MPI (Message Passing Interface) workloads by enabling concurrent collective I/O, where multiple MPI processes coordinate reads/writes for optimal efficiency.
- Data Striping Configurations Per Job: HPC administrators can tune stripe counts and sizes dynamically based on job profiles, whether the workload is I/O-intensive genomics processing or compute-heavy CFD simulations.
In advanced environments, HPE parallel file system deployments or leading open source parallel file system platforms like Lustre or BeeGFS also integrate with monitoring and telemetry tools, allowing real-time tracking of I/O performance and automatic tuning for optimal MPI throughput.
Comparing Parallel File Systems: Lustre vs BeeGFS vs GPFS vs NFS
Selecting a parallel file system depends on workload, scalability, and operational needs. HPC leaders often outperform NFS, which struggles in performance-intensive environments.
Comparison Table: Key Features at a Glance
| File System | Strengths | Weaknesses | Typical Use Cases | Parallel File System vs NFS Notes |
| Lustre | Proven scalability to exascale, high throughput, large community support | Steep learning curve, complex upgrades | HPC clusters, exascale research systems, climate modeling | Outperforms NFS by orders of magnitude in throughput and concurrency |
| BeeGFS | Flexible configuration, easier to deploy and maintain, adaptable striping | Slightly less mature for exascale-scale workloads than Lustre | Mid-to-large HPC, AI/ML training, life sciences | Parallel architecture removes NFS bottlenecks |
| IBM Spectrum Scale (GPFS) | Enterprise-grade features (multi-site replication, policy-based tiering), excellent fault tolerance | Higher licensing cost, requires advanced admin skills | Finance, media rendering, hybrid HPC-cloud | Avoids NFS single-point-of-failure via distributed metadata |
| NFS | Simplicity, ubiquity, ease of integration | Centralized metadata bottlenecks, locking contention, single point of failure | Small-scale clusters, general-purpose file sharing | Struggles with concurrency and large-scale HPC workloads |
Lustre: Widespread in Exascale Systems
Lustre is synonymous with a parallel file system in HPC. It powers many of the world’s fastest supercomputers due to its ability to scale to hundreds of petabytes and deliver multi-terabyte-per-second throughput. Its parallel global file system design allows thousands of clients to interact with data seamlessly, but it requires significant expertise to deploy and tune.
BeeGFS: Flexibility and Ease of Use
BeeGFS offers a more approachable administration experience than Lustre. It supports dynamic striping, making it ideal for environments with mixed file sizes and unpredictable I/O patterns—common in parallel file systems for life sciences, where small genome files and massive imaging datasets coexist.
IBM Spectrum Scale (GPFS): Enterprise-Level Features
GPFS (marketed as IBM Spectrum Scale) extends parallel file system capabilities into enterprise data management, offering multi-site replication, integrated policy engines, and advanced fault tolerance. It is widely used in finance, media production, and hybrid HPC-cloud workflows, bridging research and business operations.
NFS vs Parallel FS: The Bottleneck Problem
While NFS is a workhorse for shared storage in smaller environments, its centralized architecture introduces:
- Bottlenecks: All I/O requests funnel through a single metadata path.
- Locking Contention: File-level locking slows down concurrent access.
- Single Point of Failure: A failed NFS server can halt all file access.
In parallel file system vs NFS comparisons, NFS falls short for large HPC environments, where parallel architectures deliver the scalability, concurrency, and fault tolerance required for petascale and exascale workloads.
Enterprise and Vertical Use Cases

While parallel file system storage has long been associated with supercomputing centers, its benefits now extend deep into industry verticals where massive, concurrent data processing is mission-critical. From life sciences to financial markets and advanced AI/ML workflows, these systems enable data-intensive innovation at scale.
Life Sciences and Genomics
In parallel file systems for life sciences, the demands are twofold: managing millions of small files (such as genome sequence reads) and handling multi-terabyte datasets (such as microscopy or cryo-EM images). Traditional storage solutions struggle with this dual requirement due to metadata bottlenecks and sequential I/O limitations.
- Genome Sequencing Pipelines: High-throughput sequencers generate billions of reads per run. A parallel global file system accelerates read/write access for genome assembly, variant calling, and alignment steps.
- Microscopy and Imaging: Instruments like light-sheet microscopes produce petabyte-scale images that must be analyzed in parallel by HPC clusters. Striping across OSTs in a HPC parallel file system ensures both rapid access to large image stacks and high concurrency for metadata-heavy workflows.
By combining scalability with high metadata performance, open source parallel file system solutions like Lustre and BeeGFS have become the backbone of genomics and imaging research worldwide.
AI/ML Workloads
In AI, storage performance is a limiting factor for scaling training and inference workloads. Parallel file system in HPC environments provide:
- Efficient I/O for Model Training: Large deep learning models, especially large language models, require streaming vast amounts of training data to GPUs without bottlenecks.
- Support for Reinforcement Learning Environments: Parallel systems allow fast checkpointing and environment resets for large-scale simulation-based training.
- Data Parallelism at Scale: High throughput and concurrency ensure each GPU in a distributed training setup has equal, fast access to the dataset, critical for reducing idle cycles in multi-node jobs.
When we look at the difference in parallel file system vs NFS performance for AI/ML, we can see that NFS often becomes the choke point, whereas a true parallel architecture sustains the I/O needed for GPU clusters with hundreds or thousands of accelerators.
Financial Services and Simulations
Financial institutions use parallel file system storage to power data-driven decision-making where milliseconds matter.
- Risk Analysis and Monte Carlo Simulations: These workloads involve large numbers of independent calculations on shared datasets. Parallel file systems provide the concurrent access needed to scale to millions of simulations without overwhelming metadata servers.
- Real-Time Data Ingestion: Market data feeds and transaction logs arrive continuously and must be processed in parallel with analysis workloads. Striping data across multiple OSTs allows ingestion and querying to proceed simultaneously without contention.
In these enterprise contexts, whether for genomics, AI, or finance, the parallel file system architecture ensures that storage performance grows in step with computational demands, making it a critical enabler of data-intensive innovation.
Commercial and Open Source Parallel File Systems
Organizations can adopt a parallel file system via open-source solutions for cost and flexibility or commercial options with advanced features and support, depending on workload, expertise, and total cost of ownership.
Open Source Options
Open source platforms dominate in research and academic HPC deployments due to their scalability, active development communities, and ability to customize for unique workloads.
| Open Source FS | Features | Community Support Level | Flexibility |
| Lustre | Industry-standard in parallel file system in HPC, extreme scalability to exascale, high throughput | Large global community, active development via OpenSFS | Highly configurable, but complex to manage |
| BeeGFS | Dynamic striping, easier deployment, strong small file performance | Medium-large community, commercial support available | Flexible for mixed workloads like parallel file systems for life sciences |
| OrangeFS | Object-based, scalable metadata, POSIX-compliant | Smaller community, slower update cadence | Modular architecture for academic and research-focused deployments |
Open source solutions offer unmatched control over configuration and tuning, but may require specialized staff to maintain. For example, tuning parallel file system storage parameters in Lustre or BeeGFS can yield significant performance gains but demands deep technical expertise.
Commercial Offerings
Commercial vendors build on core parallel file system architecture with enterprise-ready capabilities such as graphical user interfaces (GUI), integrated tiering, proprietary performance optimizations, and 24/7 vendor support.
| Commercial FS | GUI | Tiering | Integration | Support |
| IBM Spectrum Scale (GPFS) | Yes | Policy-based tiering to cloud/object storage | Integrates with enterprise data management platforms | Global enterprise support, SLA-driven |
| WekaIO | Yes | Built-in cloud tiering | AI/ML data pipelines, container-native | 24/7 vendor-managed updates |
| Panasas | Yes | Hybrid tiering across SSD/HDD | Optimized for mixed I/O workloads | Dedicated HPC and media workflows support |
| HPE Parallel File System (ClusterStor) | Yes | Tiering with Lustre backend and object storage | Tight integration with HPE HPC hardware | Enterprise-grade lifecycle support |
Commercial solutions attract industries like finance, aerospace, and government research needing predictable performance and compliance. HPE parallel file system blends Lustre’s speed with integrated management and support, ideal for organizations that can’t afford downtime.
Choosing the Right Parallel File System: Key Criteria
Choosing the right parallel file system storage solution means balancing technical capabilities with organizational requirements. The choice should align with current workloads and projected data growth, compliance obligations, and integration strategies—whether for on-premises HPC clusters or cloud-deployed environments.
While a vital tool, HPC deployments can come with challenges. Learn how to overcome them.Uncover the latest trends in AI cloud computing and how to leverage the power of AI.

Workload Profile: Small vs. Large Files, Read/Write Balance
Different parallel file system architectures excel in different I/O patterns:
- Small File Workloads: Common in life sciences (genomic reads) or log analytics; require strong metadata performance and minimal locking overhead (BeeGFS often excels here).
- Large Sequential Files: Ideal for Lustre or GPFS, which scale throughput via wide striping across many OSTs.
- Read-Heavy Workloads: Data analysis, AI inference, and financial modeling benefit from caching strategies and high aggregate read bandwidth.
- Write-Intensive Workloads: Training deep learning models or running simulations with frequent checkpointing require high parallel write speeds and robust fault tolerance.
Performance Benchmarks and Throughput Requirements
Benchmarking is critical before committing to a platform. Measure:
- Aggregate Throughput (GB/s or TB/s)
- Latency (especially for small I/O requests)
- Concurrency Handling (thousands of clients accessing simultaneously)
Open-source tools like IOR or mdtest can evaluate a parallel file system in a HPC context, helping to identify bottlenecks before full-scale deployment.
Scalability Across Nodes and Petabytes
Ensure the file system scales linearly with:
- Number of Compute Nodes: Some solutions handle hundreds; others scale to hundreds of thousands.
- Capacity Growth: From terabytes to multiple petabytes without downtime or re-architecture.
- Metadata Scaling: Large-scale HPC workloads can overwhelm systems with centralized metadata handling (a common parallel file system vs NFS limitation).
Compliance, Encryption, Multi-Tenant Support
Industries like healthcare, finance, and government require compliance-ready storage:
- Encryption at Rest and In Transit: FIPS 140-2 and AES-256 support.
- Multi-Tenant Isolation: Logical separation of datasets for different teams or clients.
- Audit Logging and Access Control: Critical for regulated environments.
On-Prem vs. Cloud-Deployable Parallel FS
Modern parallel global file systems may run:
- On-Premises: Close to HPC compute resources for ultra-low latency.
- Cloud-Deployable: Leveraging cloud burst capabilities for temporary HPC scaling.
- Hybrid: Keeping sensitive data on-prem while using cloud for elastic workloads.
Comparative Table: Selection Criteria at a Glance
| Criteria | Lustre | BeeGFS | GPFS | HPE ClusterStor | NFS |
| Small File Performance | Moderate | High | High | Moderate | Low |
| Large File Throughput | Very High | High | Very High | Very High | Low |
| Scalability (Nodes/PB) | Excellent | Good | Excellent | Excellent | Poor |
| Ease of Management | Complex | Easy | Moderate | Easy | Easy |
| Cloud Deployment | Limited | Experimental | Supported | Limited | Widely Supported |
| Compliance Features | Add-on | Add-on | Built-in | Built-in | Limited |
| Cost | Low (OSS) | Low-Moderate | High | High | Low |
This framework ensures decision-makers choose a HPC parallel file system that matches operational demands and strategic growth plans.
Deployment Considerations and Best Practices
Deploying a parallel file system requires carefully balancing hardware architecture, network design, and operational tuning. Poor planning can bottleneck even the most capable parallel file system storage platform, while a well-architected deployment can easily sustain petascale workloads.
- Hardware Planning: The performance of a parallel file system in HPC depends on strategic hardware design. Use tiered storage—NVMe or SSD for high-I/O metadata and hot data, HDD for colder storage, and object storage for cost-effective archiving within a parallel global file system. Size metadata servers (MDS) and object storage targets (OSTs) with sufficient CPU and RAM to handle peak loads.
- Interconnects: Infiniband, NVMe Over Fabrics: Low-latency, high-bandwidth interconnects are critical. Infiniband HDR/NDR offers >200Gbps for many HPC systems, while NVMe-oF delivers NVMe speeds across fabrics. Ethernet-based clusters can use RoCE or iWARP for competitive performance without infrastructure changes.
- Networking Implications and Bandwidth Saturation: Avoid bottlenecks by isolating storage from compute traffic, using dedicated networks. Link aggregation boosts bandwidth, and topology-aware scheduling reduces cross-switch latency.
- Load Balancing, Tuning, and Striping Best Practices: Balance OST usage and tune striping per workload—wide stripes for large sequential I/O, narrow for small random I/O. Distribute files evenly and spread metadata across servers to increase concurrency. Use I/O profiling tools like Darshan or collectl to guide optimization.
- Monitoring, Logging, and Error Detection: Maintain performance with real-time dashboards, automated alerts for failures or congestion, and detailed audit logs for compliance and troubleshooting.
Conclusion
As data volumes, concurrency demands, and computational complexity grow, a well-chosen parallel file system becomes the backbone of any serious HPC infrastructure. From open-source leaders like Lustre and BeeGFS to enterprise-ready offerings such as IBM Spectrum Scale and HPE ClusterStor, these systems ensure that storage performance scales in lockstep with compute power. For organizations that need tailored, high-performance storage solutions,
PSSC Labs can design, build, and optimize HPC environments with parallel file systems tuned precisely to your workloads, ensuring maximum efficiency, reliability, and return on investment. Contact us today to get started.